

You must log in or # to comment.
deleted by creator
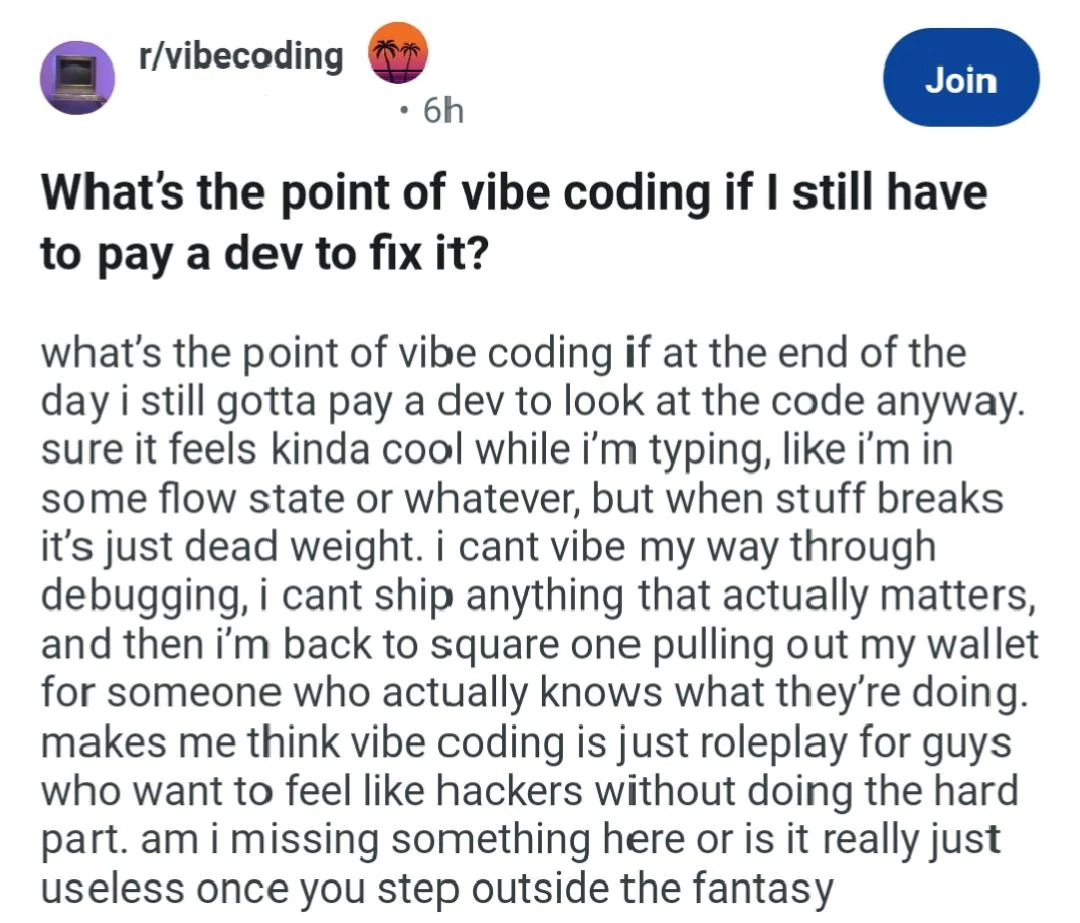
Are you saying the comment is fake, or the sentiment? This was actually posted to reddit: https://archive.is/U9ntj
Fake in that it’s almost assuredly written and posted by someone who is actively anti-vibe coding and this is a troll on the true believers.
deleted by creator
I love the one guy on that thread who is defending vibe coding, and is “about to launch his first application,” and anyone who tells him how dumb he is is only doing so because they feel threatened.
Nah I’m on that guy’s side. His experience lines up with my own, namely that vibe coding is not useful for people who don’t know how to program, but it can be useful for people who do know how to program, and simply aren’t familiar with the specific syntax used in a language they’re not an expert in.
In that case, the queries to the AI model aren’t, “write me a program that can do X”, it’s more like “write me a function in this language that can take A, B, and C as inputs, do operation Y with them, and return Z”, or “what’s the best way to find all of the unique elements in an array and sort it alphabetically in this language”. Then the programmer can take those pieces and build up a proper application with them. The AI isn’t actually writing the program for you, it’s more like a customized Stack Overflow generator, without having to wade through a decade of people arguing back and forth in the comments about inane bullshit.
Does it save a ton of time? No, but it’s still helpful, and can get you up and running in a new language much faster than the alternative.
My company is doing a big push for LLM/codegen/“everyday ‘AI’”
Sorry - threw up in my mouth a little bit there
And pretty much the only thing I acquiesce to using is the “better autocomplete” feature. Most of the other stuff it seems to offer is essentially useless on a day-to-day basis for me.
And moreover, it’s actively harmful to the entire practice of engineering, because management and execs see it as this magical oracle/panopticon that can magically make people more productive and churn out 10x more bullshit products that they didn’t consult with engineers on than before. It can’t and it doesn’t. But that doesn’t stop them from thinking it can.
And then they stop hiring junior levels because “codegen can do that”. And then you have a generational gap in the entire fucking discipline of coding as an art, because the entire fucking tech industry is doing this. And we haven’t even touched on the ecological and infrastructural (as in: water and power, not “which cloud or bare metal do we put this on”) implications and how they’re being blatantly ignored and hand-waved away, or the comical license and usage violations that are perfectly fine when large companies do but you’ve been a naughty boy if you torrent a fucking movie. But I digress.
An HtML class ten years ago isn’t anything close to knowing how to program. It’s like saying “I wrote a bullet point lost years ago so I know how to write a novel.”
I really like the description of AI coding as ‘custom stack overflow generator’ because it really sells the flaws as well, to an experienced dev. We go to stack overflow for help with some weird quirk of a language or find an obscure library that solves our specific need.
I think vibe coding is cobbling together a project from a bunch of stack overflow posts – and they only use the question part of the post.
I’m currently doing this with an angular project that’s a bit of a clusterfuck. So many layers.
I’m still having to break it down into much, much smaller chunks and it’s not able to do much, but it is helpful. Most useful thing was that I started with writing a pure SQL query with several joins and told it “turn this into linq using existing entities”.
I think they’ll completely replace ORMs.
I’m just using AI to get me the damn standard library function I want to use but can’t remember. Way faster than clicking through a couple links of a search result for it.
Sure, it can be useful for people who do know how to program, though I find it usually takes more effort to get it to create what I want and make sure it works than it takes to just do it myself.
This guy explicitly says he doesn’t know how to program though. He says he took an HTML (not a programming language, a markdown language) class a decade ago. He probably doesn’t remember shit from it, not that it’d be helpful anyway because writing HTML has nothing to do with writing a program to perform a task.
Does it save a ton of time? No, but it’s still helpful, and can get you up and running in a new language much faster than the alternative.
You obviously aren’t a programmer. You either know how to program or you don’t. The language is just syntax, which is trivial to learn. It doesn’t help you get running in a new language because you still need to learn the syntax to make sure it’s writing something reasonable. That time has to be spent no matter what.
you obviously aren’t a programmer
Don’t be a dick, the example is a perfectly reasonable one, and it’s something ppl would’ve used Rosetta code or learnxiny or stack overflow for in the past.
You should(n’t) watch Quin69. He’s currently “vibe-coding” a game with Claude. Already spent $3000 in tokens, and the game was in such a shit state, that a viewer had to intervene and push an update that dragged it to a “playable” state.
The game is at a level of a “my first godot game”, that someone who’s learning could’ve made over a weekend.
deleted by creator
I watched a bit out of curiosity and even vibe-coding aside, he is annoying as fuck. Couldn’t stand him 20 seconds.
deleted by creator
It’s strange, but I’ve seen lots of comments that are not aware this is fake. The ai hater crowd is using it as their proof, the other side saying he is using it wrong.
deleted by creator
Is that what the weird extra width on some letters is, artifacts from some AI generating the post?
No, the phrasing makes it clear someone wrote a fictional account of becoming self aware that the output of vibe coding isn’t maintainable as it scales.
I’m entirely too trusting and would like to know what about the phrasing tips you off that it’s fictional. Back on Reddit I remember so many claims about posts being fake and I was never able to tease out what distinguished the “omg fake! r/thathappened” posts from the ones that weren’t accused of that, and I feel this is a skill I should be able to have on some level. Although taking an amusing post that wasn’t real as real doesn’t always have bad consequences.
But I mostly asked because I’m curious about the weird extra width on letters.
When something is too “on the nose,” for example, it’s written in exactly the way that would induce the most cheering and virality because it appeals so much to one group of people, it’s worth considering it may have been written to provoke exactly that reaction.
Thanks!
I really wish people did not do this. This isn’t something I was ever taught to look for, and I like to think I got a good education. I was taught to make sure my source is credible, to consider biases and spin and what things are facts and what is just opinion, but I wasn’t taught to look for a lot of deception people call out online. But I guess I have to live with this and gain the skill to look for deception. Genuinely, thanks for helping me, since I don’t think I ever would have figured out what raises “fake” flags in most peoples’ heads on my own.
AmidFuror’s description is on point and I see it as a variant of Poe’s Law. Instead of sarcasm being mistaken for a real belief, it is presenting a fictional account of someone being self aware that is mistaken for someone actually becoming self aware.
There are two lines that make me absolutely certain it is written by someone who it not a vibe coder and is leaning into the sarcasm.
- ‘pulling out my wallet for someone that knows what they are doing’ implies the poster knows they don’t know what they are doing
- ‘vibe coding is just roleplaying for guys who want to feel like hackers’ is a joke I’ve seen directed at vibe coders more than once
Keep in mind that not all deception is malicious, but most people see the word deception as having a negative implication. An actor/actress pretending to be someone else is technically deceptive the same way as whoever wrote this hilarious post. They are presenting a fictional account for an audience.
You are right about the thespian thing, but when you watch TV/film/theatre everyone is in on the “joke” and we all know they’re not really falling in love, getting murdered, or whatever dramatic happening. I’m not sure if OOP is just trying to entertain and expects everyone to realize they’re joking, which would stick them on the thespian side, or if they have other motives. But hey, interesting point to bring up!
deleted by creator
r/thatHappened was the worst thing to happen to Reddit and I sincerely hate whoever created that sub
Interesting. Curious for a point of comparison how The Onion reads to you.
(Only a mediocre point of comparison I fear, but)
That’s a bit difficult because I already go into anything from The Onion knowing it’s intended to be humorous/satirical.
What I lack in ability to recognize satire or outright deception from posts written online, I make up for by reading comment threads: seeing people accuse things of being fake, seeing people defend it as true, seeing people point out the entire intention of a website is satire, seeing people who had a joke go over their heads get it explained… relying on the collective hivemind to help me out where I am deficient. It’s not a perfect solution at all, especially since people can judge wrong—I bet some “omg so fake” threads were actually real, and some astroturf-type things written to influence others without real experience behind it got through as real.
deleted by creator
deleted by creator
deleted by creator
deleted by creator
Thanks!
deleted by creator
I don’t really care about vibe coders but as a dev with just under 2 decades in the field:
- Your vibe coding shit will not go to prod until humans fully review it
- You better review it yourself first before offloading that massive mental drain to someone else (which means you still need to have some semblance of programming skills). Don’t open a PR with 250 files in it and then tell someone else to validate it.
- Use more context. Don’t give it vague ass prompts.
- Don’t use auto-accept. That’s just lazy asshole shit.
I can’t stress this enough: if you give me a PR with tons of new files and expect me to review it when you didn’t even review it yourself, I will 100% reject it and make you do it. If it’s all dumped into a single commit, I will whip your computer into the nearest body of water and tell you to go fish it out.
I don’t care what AI tool wrote your code. You’re still responsible for it and I will blame you.
When I see a sloppy PR I remind people “AI didn’t write that. You wrote it. Your name is on the git blame.”
I like this mentality. I might start telling people the same thing
Love it, I have a vibe coding colleague I will use this with.
If it’s all dumped into a single commit, I will whip your computer into the nearest body of water and tell you to go fish it out.
I’m going to steal this for an update to an internal guidance document for my dev team. Thank you.
Lmao glad I could help! I hate those big commits. They’re so much harder to traverse and know what’s going on. Developer experience has been big on my mind lately. Working 5 days a week is already hard, but there are moments when we can make tiny bits easier for each other.
I have never used an AI to code and don’t care about being able to do it to the point that I have disabled the buttons that Microsoft crammed into VS Code.
That said, I do think a better use of AI might be to prepare PRs in logical and reasonable sizes for submission that have coherent contextualization and scope. That way when some dingbat vibe codes their way into a circle jerk that simultaneously crashes from dual memory access and doxxes the entire user base, finding issues is easier to spread out and easier to educate them on why vibe coding is boneheaded.
I developed for the VFX industry and I see the whole vibe coding thing as akin to storyboards or previs. Those are fast and (often) sloppy representations of the final production which can be used to quickly communicate a concept without massive investment. I see the similarities in this, a vibe code job is sloppy, sometimes incomprehensible, but the finished product could give someone who knew what the fuck they are doing a springboard to write it correctly. So do what the film industry does: keep your previs guys in the basement, feed them occasionally, and tell them to go home when the real work starts. (No shade to previs/SB artists, it is a real craft and vital for the film industry as a whole. I am being flippant about you for commedic effect. Love you guys.)
I think this is great. I like hearing about your experience in the VFX industry since it’s unfamiliar to me as a web dev. The storyboard comparison is spot on. I like that people can drum up a “what if” at such a fast pace, but vibe coders need to be aware that it’s not a final product. You can spin it up, gauge what works and what doesn’t, and now you have feasibility with low overhead. There’s real value to that.
Edit: forgot to touch on your PR comment.
At work, we have an optional GitHub workflow that lets you call Claude in a PR and it will do its own assessment based on the instructions file we wrote for it. We stress that it’s not a final say and will make mistakes, but it’s been good in a pinch. I think if it misses 5 things but uncovers 1 bug, that’s still a win. I’ve definitely had “a-ha” moments with it where my dumb brain failed to properly handle a condition or something. Our company is good about using it responsibly and supplying as much context as we possibly can.
I think storyboards is a great example of how it could be used properly.
Storyboards are a great way for someone to communicate “this is how I want it to look” in a rough way. But, a storyboard will never show up in the final movie (except maybe fun clips during the credits or something). It’s something that helps you on your way, but along the way 100% of it is replaced.
Similarly, the way I think of generative AI is that it’s basically a really good props department.
In the past, if a props / graphics / FX department had to generate some text on a computer screen that looked like someone was Hacking the Planet they’d need to come up with something that looked completely realistic. But, it would either be something hand-crafted, or they’d just go grab some open-source file and spew it out on the screen. What generative AI does is that it digests vast amounts of data to be able to come up with something that looks realistic for the prompt it was given. For something like a hacking scene, an LLM can probably generate something that’s actually much better than what the humans would make given the time and effort required. A hacking scene that a computer security professional would think is realistic is normally way beyond the required scope. But, an LLM can probably do one that is actually plausible for a computer security professional because of what that LLM has been trained on. But, it’s still a prop. If there are any IP addresses or email addresses in the LLM-generated output they may or may not work. And, for a movie prop, it might actually be worse if they do work.
When you’re asking an AI something like “What does a selection sort algorithm look like in Rust?”, what you’re really doing is asking “What does a realistic answer to that question look like?” You’re basically asking for a prop.
Now, some props can be extremely realistic looking. Think of the cockpit of an airplane in a serious aviation drama. The props people will probably either build a very realistic cockpit, or maybe even buy one from a junkyard and fix it up. The prop will be realistic enough that even a pilot will look at it and say that it’s correctly laid out and accurate. Similarly, if you ask an LLM to produce code for you, sometimes it will give you something that is realistic enough that it actually works.
Having said that, fundamentally, there’s a difference between “What is the answer to this question?” and “What would a realistic answer to this question look like?” And that’s the fundamental flaw of LLMs. Answering a question requires understanding the question. Simulating an answer just requires pattern matching.
deleted by creator
See, I agree with everything up to the end. There you are getting into the philosophy of cognition. How do humans answer a question? I would argue, for many, the answer for most topics would be "I am repeating what I was taught/learned/read. An argument could be made that your description of responding with “What would a realistic answer to this question look like?” is fundamentally symmetric with “This is what I was taught.” Both are regurgitating information fed to them by someone who presumably (hopefully) actually had a firm understanding of the material themselves. As an example: we are all taught that 2+2=4, but most people are not taught WHY 2+2=4. Even fewer are taught that 2+2=11 in base 3 or how to convert bases at all. So do people “know” that 2+2=4 or are they just repeating the answer that they were told was correct?
I am not saying that LLMs understand or know anything, I am saying that most humans don’t either for most topics.
How do humans answer a question? I would argue, for many, the answer for most topics would be "I am repeating what I was taught/learned/read.
Even children aren’t expected to just repeat verbatim what they were taught. When kids are being taught verbs, they’re shown the pattern: “I run, you run, he runs; I eat, you eat, he eats.” They’re are told that there’s a pattern, and it’s that the “he/she/they” version has an “s” at the end. They now understand some of how verbs work in English, and can try to apply that pattern. But, even when it’s spotting a pattern and applying the right rule, there’s still an element of understanding involved. You have to recognize that this is a “verb” situation, and you should apply that bit about “add an ‘s’ if it’s he/she/it/they”.
An LLM, by contrast, never learns any rules. Instead it ingests every single verb that has ever been recorded in English, and builds up a probability table for what comes next.
but most people are not taught WHY 2+2=4
Everybody is taught why 2+2=4. They normally use apples. They say if I have 2 apples and John has 2 apples, how many apples are there in total? It’s not simply memorizing that when you see the token “2” followed by “+” then “2” then “=” that the next likely token is a “4”.
If you watch little kids doing that kind of math, they do understand what’s happening because they’re often counting on their fingers. That signals that there’s a level of understanding that’s different from simply pattern matching.
Sure, there’s a lot of pattern matching in the way human brains work too. But, fundamentally there’s also at least some amount of “understanding”. One example where humans do pattern matching is idioms. A lot of people just repeat the idiom without understanding what it really means. But, they do it in order to convey a message. They don’t do it just because it sounds like it’s the most likely thing that will be said next in the current conversation.
I wasn’t attempting to attack what you said, merely pointing out that once you cross the line into philosophy things get really murky really fast.
You assert that LLMs aren’t taught the rules, but every word is not just a word. The tokenization process includes part of speech tagging, predicate tagging, etc. The ‘rules’ that you are talking about are actually encapsulated in the tokenization process. The way the tokenization process for LLMs, at least as of a few years ago when I read a textbook on building LLMs, is predicated on the rules of the language. Parts of speech, syntax information, word commonality, etc. are all major parts of the ingestion process before training is done. They may not have had a teacher giving them the ‘rules’, but that does not mean it was not included in the training.
And circling back to the philosophical question of what it means to “learn” or “know” something, you actually exhibited what I was talking about in your response on the math question. Putting to piles of apples on a table and counting them to find the total is a naïve application of the principals of addition to a situation, but it is not describing why addition operates the way it does. That answer does not get discussed until Number Theory in upper division math courses in college. If you have never taken that course or studied Number Theory independently, you do not know ‘why’ adding two numbers together gives you the total, you know ‘that’ adding two numbers together gives you the total, and that is enough for your life.
Learning, and by extension knowledge, have many forms and processes that certainly do not look the same by comparison. Learning as a child is unrecognizable when compared directly to learning as an adult, especially in our society. Non-sapient animals all learn and have knowledge, but the processes for it are unintelligible to most people, save those who study animal intelligence. So to say the LLM does or does not “know” anything is to assert that their “knowing” or “learning” will be recognizable and intelligible to the lay man. Yes, I know that it is based on statistical mechanics, I studied those in my BS for Applied Mathematics. I know it is selecting the most likely word to follow what has been generated. The thing is, I recognize that I am doing exactly the same process right now, typing this message. I am deciding what sequence of words and tones of language will be approachable and relatable while still conveying the argument I wish to levy. Did I fail? Most certainly. I’m a pedantic neurodivergent piece of shit having a spirited discussion online, I am bound to fail because I know nothing about my audience aside from the prompt to which you gave me to respond. So I pose the question, when behaviors are symmetric, and outcomes are similar, how can an attribute be applied to one but not the other?
I like your previs analogy, because that’s how I’ve been thinking of it in my head without really knowing how to communicate it. It’s not very good at making a finished project, but it can be useful to demonstrate a direction to go in.
And actually, the one time I’ve felt I was able to use AI successfully was literally using it for previs; I had a specific idea of design I wanted for a logo, but didn’t know how to communicate it. So I created about a hundred AI iterations that eventually got close to what I wanted, handed that to my wife who is an actual artist, told her that was roughly what I was thinking about, and then she took the direction it was going in and made it an actual proper finished design. It saved us probably 15-20 iterations of going back and forth, and kept her from getting progressively more annoyed with me for saying “well… can you make it like that, but more so?”
It is not useless. You should absolutely continue to vibes code. Don’t let a professional get involved at the ground floor. Don’t inhouse a professional staff.
Please continue paying me $200/hr for months on end debugging your Baby’s First Web App tier coding project long after anyone else can salvage it.
And don’t forget to tell your investors how smart you are by Vibes Coding! That’s the most important part. Secure! That! Series! B! Go public! Get yourself a billion dollar valuation on these projects!
Keep me in the good wine and the nice car! I love vibes coding.
Not me, I’d rather work on a clean code base without any slop, even if it pays a little less. QoL > TC
I’m not above slinging a little spaghetti if it pays the bills.
Also, don’t waste money on doctor visits. Let Bing diagnose your problems for pennies on the dollar. Be smart! Don’t let some doctor tell you what to do.
IANAL so: /s
Kinda hard to find jobs right now in the midst of all this but looking forward to the absolutely inevitable decade long cleanup.
My entire IT career has been funded by morons like this. This is just the latest moronic idea that is going to pay my bills. Cleaning up after vibe coders has guaranteed my income until I die. You see, posts like this focus on the code that is broken and requires another dev to fix it enough to get it going. There is a long road from “finally working” to “production ready” to “optimized”, and we get paid along every inch of the way.
Why does this image look like an AI-generated screenshot? The letter spacing and weights are all wrong.
It’s a real post on Reddit. I don’t know what combination of screenshotting/uploading tools leads to this kind of mangling, but I’ve seen it in screenshots from Android, too. The artifacts seem to run down in straight vertical lines, so maybe slight scaling with a nearest-neighbor algorithm (in 2025?!?) plus a couple levels of JPEG compression? It looks really weird.
I’m curious. If anyone knows, please enlighten me!
Oh, if it’s just a random Android fork/version being terrible at something, I understand now. Maybe it’s a phone with a screen that isn’t standard in someway.
probably
So there are multiple people in this thread who state their job is to unfuck what the LLMs are doing. I have a family member who graduated in CS a year ago and is having a hell of a time finding work, how would he go about getting one of these “clean up after the model” jobs?
Has he tried being a senior developer? He should really try being a senior developer.
He needs at least a decade of industry experience. That helps me find jobs.
It would be nice if software development were a real profession and people could get that experience properly.
It was. Wall St is destroying it, along with everything else in its insatiable drive for more profit. Everything must be sacrificed to the golden idol.
It makes me so mad that there are CS grads who can’t find work at the same time as companies are exploiting the H1B process saying “there aren’t enough applicants”. When are these companies going to be held accountable?
Never, they donate to get the politicians reelected.
This is in no way new. 20 years ago I used to refer to some job postings as H1Bait because they’d have requirements that were physically impossible (like having 5 years experience with a piece of software <2 years old) specifically so they could claim they couldn’t find anyone qualified (because anyone claiming to be qualified was definitely lying) to justify an H1B for which they would be suddenly way less thorough about checking qualifications.
It’s so much worse than it was. AIs have absolutely murdered entry-level positions
Yeah companies have always been abusing H1B, but it seems like only recently is it so hard for CS grads to find jobs. I didn’t have much trouble in 2010 and it was easy to hop jobs for me the last 10 years.
Now, not so much.
After they fill up on H1B workers and find out that only 1/10 is a good investment.
H1B development work has been a thing for decades, but there’s a reason why there are still high-paying development jobs in the US.
The difficult part is going to be that new engineers are not generally who people think about to unfuck code. Even before the LLMs junior engineers are generally the people that fuck things up.
It’s through fucking lots of stuff up and unfucking that stuff up and learning how not to fuck things up in the first place that you go from being a junior engineer to a more senior engineer. Until you land in a lofty position like staff engineer and your job is mostly to listen to how people want to fuck everything up and go “maybe let’s try this other way that won’t fuck everything up instead”
Tell your family member to network, that’s the best way to get a job. There are discord servers for every programming language and most projects. Contribute to open source projects and get to know the people.
Build things, write code, open source it on GitHub.
Drill on leet code questions, they aren’t super useful, but in any interview at least part of the assessment is going to be how well they can do on those.
There are still plenty of places hiring. AI has just made it so that most senior engineers have access to a junior engineer level programmer that they can give tasks to at all time, the AI. So anything you can do to stand out is an advantage.
No idea, but I am not sure your family member is qualified. I would estimate that a coding LLM can code as well as a fresh CS grad. The big advantage that fresh grads have is that after you give them a piece of advice once or twice, they stop making that same mistake.
Where is this coming from? I don’t think an LLM can code at the level of a recent cs grad unless it’s piloted by a cs grad.
Maybe you’ve had much better luck than me, but coding LLMs seem largely useless without prior coding knowledge.
What’s this based on? Have you met a fresh CS graduate and compared them to an LLM? Does it not vary person to person? Or fuck it, LLM to LLM? Calling them not qualified seems harsh when it’s based on sod all.
Answer is probably the same as before AI: build a portfolio on GitHub. These days maybe try to find repos that have vibe code in them and make commits that fix the AI garbage.
Answer is probably the same as before AI: build a portfolio on GitHub
You really think that using GitHub falls in the usual vibecoding toolbox? As in: would they even know where/how to look?
You think vibe coders don’t love the smell of their own shit enough to show it to the world?
My path was working for a consulting firm (Accenture) for a few years, making friends with my clients, and then jumping to freelance work a few years later when I can get paid my contract rate directly rather than letting Accenture take a big chunk of it.
Working with Accenture
I am so sorry…
It was a wild ride
No idea, but I am not sure your family member is qualified. I would estimate that a coding LLM can code as well as a fresh CS grad. The big advantage that fresh grads have is that after you give them a piece of advice once or twice, they stop making that same mistake.
a coding LLM can code as well as a fresh CS grad.
For a couple of hundred lines of code, they might even be above average. When you split that into a couple of files or start branching out, they usually start to struggle.
after you give them a piece of advice once or twice, they stop making that same mistake.
That’s a damn good observation. Learning only happens with re-training and that’s wayyy cheaper when done in meat.
I’ve been an engineer for over a decade and am now having a hard time finding work because of this LLM situation so I can’t imagine how a fresh graduate must feel.
As a software developer, I’ve found some free LLMs to provide productivity boosts. It is a fairly hairpulling experience to not try too hard to get a bad LLM to correct itself, and learning to switch quickly from bad LLMs is a key skill in using them. A good model is still one that you can fix their broken code, and ask them to understand why what you provided them fixes it. They need a long context window to not repeat their mistakes. Qwen 3 is very good at this. Open source also means a future of customizing to domain, ie. language specific, optimizations, and privacy trust/unlimited use with enough local RAM, with some confidence that AI is working for you rather than data collecting for others. Claude Sonnet 4 is stronger, but limited free access.
The permanent side of high market cap US AI industry is that it will always be a vector for NSA/fascism empire supremacy, and Skynet goal, in addition to potentially stealing your input/output streams. The future for users who need to opt out of these threats, is local inference, and open source that can be customized to domains important to users/organizations. Open models are already at close parity, IMO from my investigations, and, relatively low hanging fruit, customization a certain path to exceeding parity for most applications.
No LLM can be trusted to allow you do to something you have no expertise in. This state will remain an optimistic future for longer than you hope.
I think the key to good LLM usage is a light touch. Let the LLM know what you want, maybe refine it if you see where the result went wrong. But if you find yourself deep in conversation trying to explain to the LLM why it’s not getting your idea, you’re going to wind up with a bad product. Just abandon it and try to do the thing yourself or get someone who knows what you want.
They get confused easily, and despite what is being pitched, they don’t really learn very well. So if they get something wrong the first time they aren’t going to figure it out after another hour or two.
In my experience, they’re better at poking holes in code than writing it, whether that’s green or brownfield.
I’ve tried to get it to make sections of changes for me, and it feels very productive, but when I time myself I find I spend probably more time correcting the LLM’s work than if I’d just written it myself.
But if you ask it to judge a refactor, then you might actually get one or two good points. You just have to really be careful to double check its assertions if you’re unfamiliar with anything, because it will lead you to some real boners if you just follow it blindly.
At work we’ve got coderabbit set up on our github and it has found bugs that I wrote. Sometimes the thing drives me insane with pointless comments, but just today found a spot that would have been a big bug in prod in like 3 months.
But if you find yourself deep in conversation trying to explain to the LLM why it’s not getting your idea, you’re going to wind up with a bad product.
Yes. Kind of. It takes ( a couple of days) experience with LLMs to know that failing to understand your corrections means immediate delete and try another LLM. The only OpenAI llm I tried was their 120g open source release. It insisted that it was correct in its stupidity. That’s worse than LLMs that forget the corrections from 3 prompts ago, though I also learned that is also grounds for delete over any hope for their usefulness.
Swear to god the vibe coding movement is going to create so many new jobs in the ilk of “I hired some dude to write my startup thing and now it’s gone all to shit, can you make it actually good and scalable and responsive please?”
"What do you do? “Oh, I work in AI Disaster Response”
Best erotic story ever on !DevsGoneWild@lemmynsfw.com <3
I wish that was a real sub
Somebody make this a sub pls
It’s like the nerd version of Synthol body ‘builders’.
Well
That’s horrifying. I thought it was way cooler that I could make my own muscles bigger by diet and exercise but maybe cool is different in different parts of the world
That’s horrifying.
I have no empirical evidence… but I’m fully convinced there’s at least 1 idiot with a synthol pp
I would not be a slight bit surprised if all of those guys tried to have a synthol pp.
AI used extremely sparingly is sometimes helpful to an experienced coder. “Multivac, generate a set of unit tests for this function.” Okay, some of these are dumb, but it’s easier getting started on this mess than just looking at a blank buffer. Helps get the juices flowing a bit. But man, you try to actually do anything with it, and suddenly you’re lost chasing a will-o’-wisp.
Oh man, I love ChatGPT for one thing in particular: “Hey chatbot, is there some library or standard library function for that very specific, yet still kinda generic thing I’m trying to do, so that I don’t have to write it myself?”
It does frequently give a helpful answer. That is, it doesn’t give me working code, but a helpful pointer to some manual where I can find good instructions for how to use the thing to solve my problem.
I will usually google that kind of thing first (to save the rainforests)… Often I can find something that way, otherwise I might try an LLM
True that. But I often find that the search engine is not very good at giving me a solution if I don’t know the name of a problem and only have my spaghetti thoughts on what the thing is supposed to do, and translating spaghetti thoughts into something a search engine can find is where the chatbot excels.
Part of your trouble there is that Google is absolute dog shit these days. It used to be like magic; simple search terms would find you exactly what you were looking for in the first handful of results. Now you’re lucky to find it on the second page.
Google has become so shit though
I don’t want to dismiss your point overall, but I see that example so often and it irks me so much.
Unit tests are your specification. So, 1) ideally you should write the specification before you implement the functionality. But also, 2) this is the one part where you really should be putting in your critical thinking to work out what the code needs to be doing.
An AI chatbot or autocomplete can aid you in putting down some of the boilerplate to have the specification automatically checked against the implementation. Or you could try to formulate the specification in plaintext and have an AI translate it into code. But an AI without knowledge of the context nor critical thinking cannot write the specification for you.
Unit tests become the specification once they are written. ChatGPT can easily write unit tests from whatever your specification is before that – such as documentation, a bunch of comments and stubs, or even a first draft of the function itself, given enough context from the rest of the project.
Unit tests are too klunky to think in. You don’t prototype the specification by implementing unit tests. And you really only lay down a few critical paths even if you “write the tests first” because code paths always come up during implementation that demand more test coverage anyway.
Also after your 4th proper project you won’t be as confused about “how to get started” anymore anyway.
You have a language of choice, a gui framework, and a build system you are comfortable with in mind already just start making folders.
Feels like there are some fine people here only working on new projects. Getting started could be, breaking down a 20 year old program, written in some wierd manner because the original developer use to do functional programming but was told to use java and oop. No comments, no tests, no normal patterns, no documentation.
The argument was “AI helps when starting up new projects by making unit tests etc.”
Also for not 20, but even building 10 year old libraries using AI is unhelpful. It just keeps hallucinating non-existent packages and functions.
At this point just drive yourself crazy while promising to become goose farmer and commenting every single line in your own words like god intended for programmers to do.
You read “new projects” in, actually. And the whole unit test thing was just an example demonstrating how AI use has to be tightly bounded to be arguably useful.
Tests are probably both the best and worst things to use LLMs for.
They’re the best because of all the boilerplate. Unit tests tend to have so much of that, setting things up and tearing it down. You want that to be as consistent as possible so that someone looking at it immediately understands what they’re seeing.
OTOH, tests are also where you figure out how to attack your code from multiple angles. You really need to understand your code to think of all the ways it could fail. LLMs don’t understand anything, so I’d never trust one to come up with a good set of things to test.
imo paying devs to review vibe coded bile would not work either. At best, the dev themselves should do the vibe coding.
Someone who has no clue whatsoever in terms of programming cannot give it the right prompt.
Yeah, this is my nightmare scenario. Code reviews are always the worst part of a programming gig, and they must get exponentially worse when the junior devs can crank out 100s of lines of code per commit with an LLM.
Also, LLMs are essentially designed to produce code that will pass a code review. It’s output that is designed to look as realistic as possible. So, not only do you have to look through the code for flaws, any error is basically “camouflaged”.
With a junior dev, sometimes their lack of experience is visible in the code. You can tell what to look at more closely based on where it looks like they’re out of their comfort zone. Whereas an LLM is always 100% in its comfort zone, but has no clue what it’s actually doing.
Vibe coding is useful for super basic bash scripting and that’s about it. Even that it will mess up but usually in a suler easily fixed way
I don’t think it has much to do with how “complex or not” it is, but rather how common it is.
It can completely fail on very simple things that are just a bit obscure, so it has too little training data.
And it can do very complex things if there’s enough training data on those things.
Yes exactly.
“Implement a first order lowpass filter in C”
LLM has no issue.
“Implement a string reversal function in Wren”
LLM proceeds to output an unholy mix of python and JavaScript.
Even though the second task is trivial compared to the first, LLMs have almost no training data on Wren (an obscure semi-dead language).
I’ve also found it useful for simple Python scripts when I need to analyze data. I don’t use pandas/scipy/numpy/matplotlib enough to remember the syntax and library functions. With vibe coding it, I can have a script in minutes for reading a csv with weird timestamps, scale some of the channels, filter out noise or detrending, perform a Fourier transform, and do a curve fit towards a model.
But then obviously I know every intermediate step I want to do.
When I want to be lazy and make some simple excel macros is about the most iv trusted it with that it manages to do with out fucking up and taking more time then just doing it my self.
I’m sure it’s fun to see a series of text prompts turn into an app, but if you don’t understand the code and can’t fix it when it doesn’t work without starting over, you’re going to have a bad time. Sure, it takes time and effort to learn to program, but it pays off in the end.
Yeah, mostly agreed. In my experience so far, an experienced dev that’s really putting time into their setup can greatly accelerate their output with these tools, while an inexperienced dev will end up taking way longer (and they’ll understand less) than it would have if they worked normally
Clearly satire
It’s kind of hard for me to tell on this one. Maybe the boomer lead is seeping into my brain.
Nah, it’s the microplastics.
Why not both ™?
With a pinch of PFAS for good measure?
What is good enough for the goose is good for the gander
Microplastics are stored in the balls.
I agree, the terminology used gives it away.



















{kind=link}